GRs综述1 A Survey on Large Language Models for Recommendation
2024 中国科学技术大学 LLM4Rec-Awesome-Paper
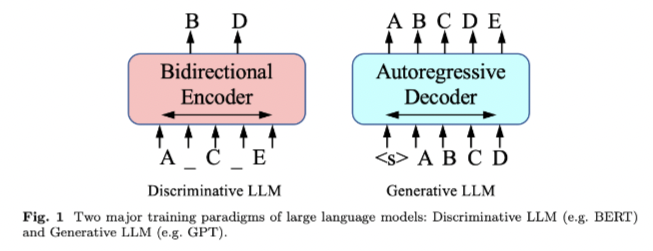
本文将LLM视为具有大量参数的基于Transformer的模型,使用自/半监督学习技术在海量数据集上进行训练,例如BERT、GPT系列、PaLM系列等。
1# 基于建模范式
建模范式(Modeling Paradigms)关注的是推荐系统中模型的基本结构和工作原理。
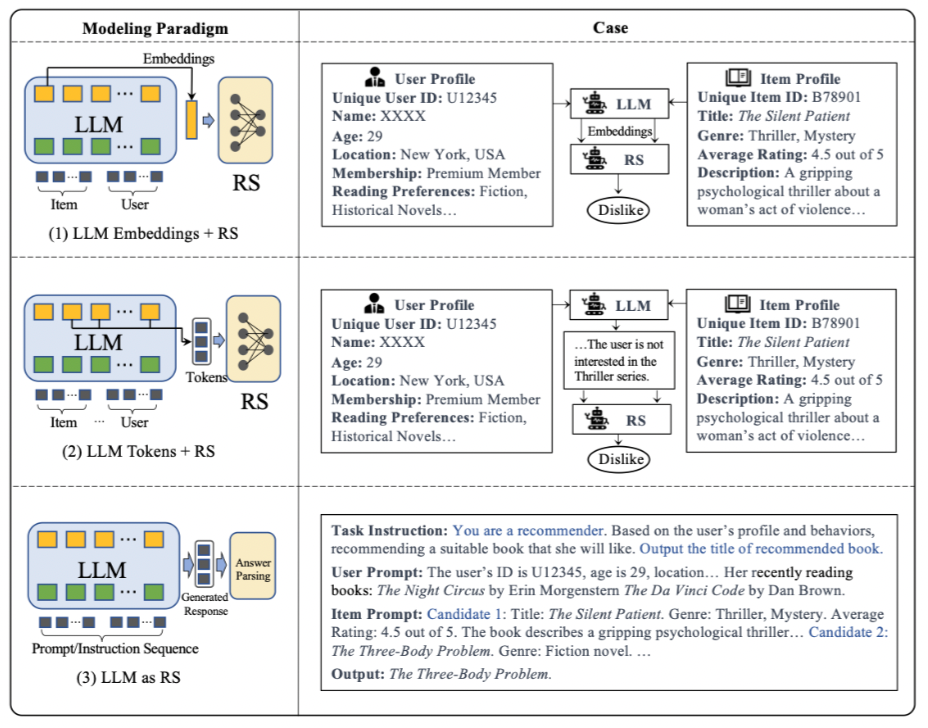
- LLM Embeddings + RS:将LLM作为特征提取器,将物品和用户的文本特征输入LLM,然后输出相应的嵌入向量,这些嵌入向量被用于传统的推荐系统模型。
- LLM Tokens + RS:类似于第一种方法,但这种方法基于输入物品和用户特征生成的令牌,通过语义挖掘捕获潜在的偏好,并将这些信息集成到推荐系统的决策过程中。
- LLM as RS:与前两种方法不同,这一范式旨在直接将预训练的LLM转换为强大的推荐系统。输入序列通常包括用户画像描述、行为提示和任务指令,输出序列预期提供合理的推荐结果。
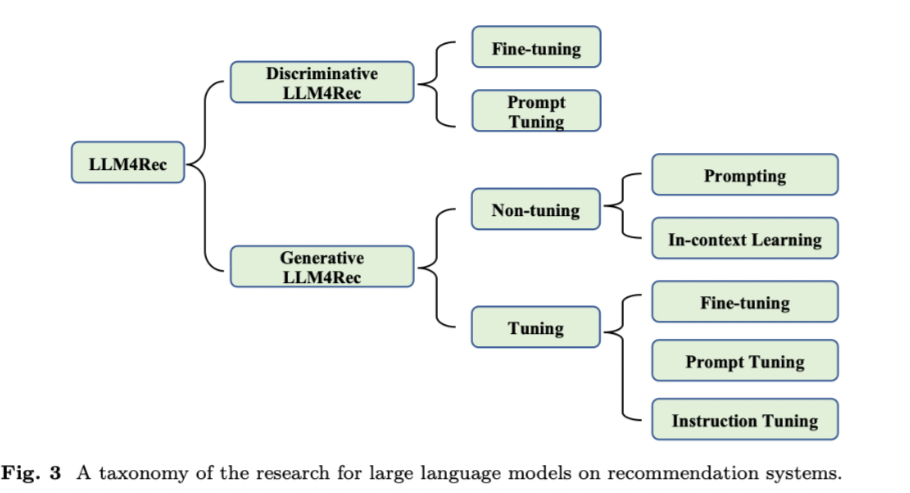
在实际应用中,大型语言模型的选择会显著影响推荐系统中建模范式的设计。如图3所示,在本文中,我们将现有的工作分为两大类,分别是用于推荐系统的判别式LLM和生成式LLM。
2# 基于训练范式
训练范式(Training Paradigms)则侧重于模型如何通过不同的训练方法或策略来适应特定的推荐任务。
- 判别式LLM(Discriminative LLMs):主要关注于如何通过微调等技术,使LLM更好地适应推荐任务,例如通过微调来对齐预训练模型的表示与特定领域的数据。
- 生成型LLM(Generative LLMs):侧重于使用LLM的文本生成能力来直接生成推荐结果。根据是否调整模型参数,生成型LLM的应用可以进一步细分为非调整范式(如直接使用LLM的零样本能力)和调整范式(如微调、提示调整和指令调整)。
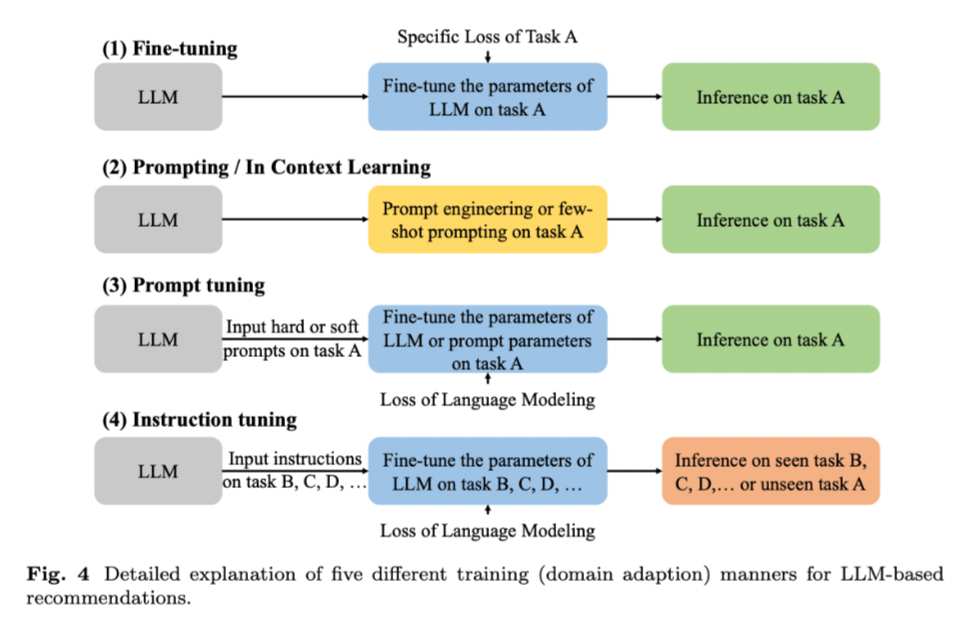
而大模型的训练方式可以更细致的分类,展示了LLM在推荐系统中的几种不同的训练(或领域适应)方式。这些方式根据是否对模型参数进行调整以及如何调整,可以进一步细分为:
- 微调(Fine-tuning):在特定任务上进一步训练预训练的LLM,以调整模型参数。
- 提示/上下文学习(Prompting / In Context Learning):使用特定的提示或示例来引导LLM完成推荐任务,而不改变模型参数。
- 提示调整(Prompt Tuning):调整提示或指令的参数,以改善LLM在推荐任务上的表现。
- 指令调整(Instruction Tuning):针对不同的任务指令微调LLM,以提高其在多样化任务上的泛化能力。
一般来说,判别型语言模型非常适合(1)Fine-tuning,而生成性大型语言模型的响应生成能力进一步支持范式(2)Prompting 或(3)Prompt Tuning
3# 判别式(Discriminative)
主要是指BERT系列的那些模型,由于判别语言模型在自然语言理解任务中的专业知识,它们通常被认为是不同下游任务的embedding基础。
推荐系统也是如此。大多数现有工作通过微调(fine-tuning)将BERT等预训练模型的表示与特定领域的数据对齐。一些研究还探索了其他训练策略,如提示调整(prompt tuning)和适配器调整(adapter tuning)。
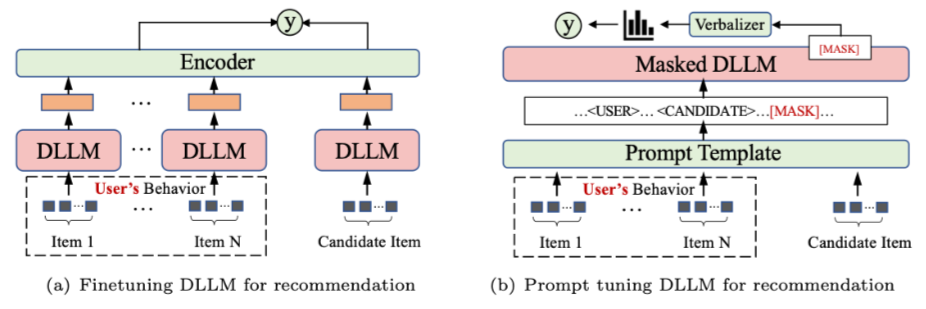
3.1# 微调(fine-tuning)
微调背后的想法是采用一个语言模型,该模型已经从大规模文本数据中学习了丰富的语言表示,并通过在特定任务的数据上进一步训练来将其适应特定任务或领域。如图5(a)所示。
微调过程包括用其学习的参数初始化预先训练的语言模型,然后在特定于推荐的数据集上对其进行训练。该数据集通常包括user-item交互、item的文本描述、user配置文件和其他相关上下文信息。
在微调过程中,模型的参数会根据特定任务的数据进行更新,使其能够适应目标推荐任务并进行专门化。预训练和微调阶段的学习目标可能会有所不同,因为它们针对不同的优化目标。
Adapter Tuning 是一种针对预训练语言模型的微调方法,它专注于调整模型中的一小部分参数,而不是整个网络。这种方法通常用于将预训练的大型语言模型(LLM)适应特定的下游任务,如推荐系统,同时保持模型的大部分原始参数不变。
在 Adapter Tuning 中,会在模型的特定部分(通常是某些层或模块)添加小型的可训练适配器(adapter)模块。这些适配器模块的参数数量相对于整个模型来说是非常少的,因此这种方法是参数高效的。适配器模块被训练以学习特定任务的特定表示,而模型的其余部分则保持不变,这样可以保留预训练模型在通用语言理解方面的强大能力。
3.2# 提示调整(prompt tuning)
提示调整的目的不是通过设计特定的目标函数使LLM适应不同的下游推荐任务,而是使用硬/软提示和标签词描述器(label word verbalizer),使推荐调整的目标与预先训练的损失保持一致。
如图5(b)所示,由于DLLM中常用的基于掩码的训练,所提到的描述器的作用是在DLLM在[mask]位置预测的单词和实际标签之间建立映射。这种关联允许语言模型和任务之间的链接,确保它们的一致性。
4# 生成式(Generative)
与大多数基于判别模型的方法不同(将LLM学习的表示与推荐域对齐的),大多数基于生成模型的工作将推荐任务转换为自然语言任务,然后应用上下文学习、提示调整和指令调整等技术来适配LLM以直接生成推荐结果。
如图3所示,根据是否调整参数,这些基于生成LLM的方法可以进一步细分为两种范式:非调整范式和调整范式(non-tuning paradigm and tuning paradigm)。
4.1# 非调整范式(non-tuning paradigm)
LLM在许多未知的任务中显示出强大的zero/few-shot能力。因此,最近的一些工作假设LLM已经具有推荐能力,并试图通过引入特定的提示来触发这些能力。他们采用了最近的教学和情境学习实践,在不调整模型参数的情况下,将LLM用于推荐任务。
根据提示是否包括演示示例,该范式下的研究主要分为以下两类:提示(Prompting)和上下文学习(in-context learning)。
4.1.1# 提示(Prompting)
这类工作旨在设计更合适的说明和提示,帮助LLM更好地理解和解决推荐任务。
除了将LLM作为推荐系统外,一些研究还利用LLM构建模型特征来改进传统的推荐系统。
在实践中,除了排名模型之外,整个推荐系统通常由多个重要组件组成,如内容数据库和候选检索模型。因此,使用LLM进行推荐的另一条途径是将它们作为整个系统的控制器。
GeneRec[68]提出了一个生成推荐框架,并使用LLM来控制何时通过AIGC模型推荐现有item或生成新item。
UniLLMRec[72]没有使用LLM作为控制器,而是提出了一种端到端的链式推荐框架,该框架利用LLM有效地集成召回、排序和重新排序任务。总之,这些研究采用自然语言提示,利用LLM的zero-shot功能进行推荐任务,提供了一种具有成本效益和实用性的方法。
4.1.2# 上下文学习(in-context learning)
上下文学习是GPT-3和其他LLM用于快速适应新任务和信息的技术。通过一些演示输入标签对,它们可以预测看不见的输入的标签,而无需额外的参数更新。因此,一些工作试图在提示中添加演示示例,以使LLM更好地理解推荐任务。
4.2# 调整范式(tuning paradigm)
如上所述,通过适当的提示设计,其推荐性能可以显著超过随机猜测。然而,以这种方式构建的推荐系统在特定数据上不能超过专门为给定任务训练的推荐模型的性能。
因此,许多研究人员旨在通过进一步的微调或及时学习来提高LLM的推荐能力。在本文中,我们将调整方法的范式分为三种不同的类型,分别是微调、提示调整和指令调整。
在微调范式中,判别性和生成性大语言模型的使用方法明显相似。LLM主要用作编码器来提取user或item的表示,并且LLM的参数随后根据下游推荐任务的特定损失函数进行微调。
在提示调整和指令调整范式中,大型模型的输出是一致的文本,并且使用语言建模的损失来训练它们的参数。
提示调整和指令调整训练范式之间的主要区别在于,提示调整主要关注特定任务,例如评分预测,而LLM在指令调整范式下针对具有不同类型指令的多个任务进行训练。因此,LLM可以通过指令调整获得更好的零样本能力。
4.2.3# 指令调整(Instruction Tuning)
在这个范式中,LLM被微调为具有不同类型指令的多个任务。通过这种方式,LLM可以更好地与人类意图保持一致,并实现更好的零样本能力。
例如,[2]提出在五种不同类型的指令上微调T5模型,分别是顺序推荐、评分预测、解释生成、评论摘要和直接推荐。在对推荐数据集进行多任务指令调整后,该模型可以实现对看不见的个性化提示和新item的零样本泛化能力。
5# 技术挑战
5.1# Bias
Position Bias。在推荐系统的生成语言建模范式中,用户行为序列和推荐候选者等各种信息以文本顺序描述的形式输入到语言模型,这可能会引入语言模型本身固有的一些位置偏差。
Popularity Bias。LLM的排名结果受候选的受欢迎程度的影响。在LLM的预训练语料库中经常被广泛讨论和提及的热门item往往排名更高。这可能导致结果缺乏多样性,并可能使不太受欢迎或少数群体边缘化。
Fairness Bias。预训练的语言模型表现出与敏感属性相关的公平性问题,这些敏感属性受到训练数据或参与某些任务注释的个人的人口统计数据的影响。这些公平性问题可能导致模型提出假设用户属于特定群体的建议,在商业部署时可能会导致有争议的问题。一个例子是由性别或种族引起的推荐结果中的偏见。
Personalization Bias。将协同过滤引入用于推荐目的的大型语言模型(LLM)带来了一些挑战,特别是与传统的基于ID的推荐模型相比。虽然LLM有潜力通过理解细微的文本输入来生成高度个性化的内容,但将这种能力转化为个性化推荐是一项挑战。传统模型直接映射user-item交互,有时可以更直接地个性化推荐。
5.2# Prompt
User/Item Representation。在实践中,推荐系统通常利用大量离散和连续的特征来表示user和item。然而,大多数现有的基于LLM的工作只使用名称来表示item,并使用item名称列表来表示用户行为,这不足以准确地对user和item进行建模。此外,将用户的异构行为序列(如点击、添加到购物车和电子商务领域的购买)转换为用于偏好建模的自然语言至关重要。在传统的推荐模型中,类ID功能已被证明是有效的,但将其纳入提示中以提高个性化推荐性能也是一项挑战。
Limited Context Length。LLM的上下文长度限制将限制用户行为序列的长度和候选item的数量,从而导致次优性能。现有工作已经提出了一些技术来缓解这个问题,例如从用户行为序列中选择有代表性的item或者滑动窗口。
相关工作
[9] Lin, J., Dai, X., Xi, Y., Liu, W., Chen, B., Zhang, H., Liu, Y., Wu, C., Li, X., Zhu, C., Guo, H., Yu, Y., Tang, R., Zhang, W.: How Can Recommender Systems Benefit from Large Language Models: A Survey (2024)
[10] Zhao, Z., Fan, W., Li, J., Liu, Y., Mei, X., Wang, Y., Wen, Z., Wang, F., Zhao, X., Tang, J., Li, Q.: Recommender Systems in the Era of Large Language Models (LLMs) (2024)
[11] Li, L., Zhang, Y., Liu, D., Chen, L.: Large Language Models for Generative Recommendation: A Survey and Visionary Discussions (2024)
[12] Chen, J., Liu, Z., Huang, X., Wu, C., Liu, Q., Jiang, G., Pu, Y., Lei, Y., Chen, X., Wang, X., Lian, D., Chen, E.: When Large Language Models Meet Personalization: Perspectives of Challenges and Opportunities (2023)
[68] Wang, W., Lin, X., Feng, F., He, X., Chua, T.: Generative recommendation: Towards next-generation recommender paradigm. CoRR abs/2304.03516 (2023)
[72] Zhang, W., Wu, C., Li, X., Wang, Y., Dong, K., Wang, Y., Dai, X., Zhao, X., Guo, H., Tang, R.: Tired of plugins? large language models can be end-to-end recommenders. CoRR abs/2404.00702 (2024)
[2] Geng, S., Liu, S., Fu, Z., Ge, Y., Zhang, Y.: Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). In: RecSys, pp. 299–315 (2022)